縣委書記代軍率隊深入龍華鎮,就該鎮經濟社會發展,特別是重點旅游開發項目的策劃與規劃工作,開展專題調研和現場辦公。代軍強調,要立足龍華鎮獨特的自然稟賦與人文底蘊,高標準、高質量推進旅游項目開發,為縣域經濟高質量發展注入新動能。
調研期間,代軍一行實地考察了龍華鎮擬重點開發的旅游景觀區域、歷史文化遺址及周邊基礎設施現狀。每到一處,代軍都仔細察看地形地貌,詳細了解資源特點、開發現狀與保護情況,并與鎮村干部、當地群眾及隨行專家深入交流,聽取他們對旅游發展的想法與建議。
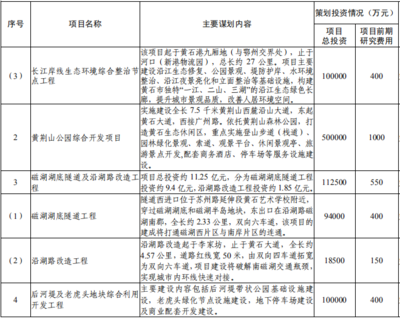
在隨后召開的專題座談會上,代軍認真聽取了龍華鎮黨委政府關于經濟社會發展情況,特別是旅游產業發展思路和重點項目策劃方案的匯報。與會相關部門負責人和受邀的旅游規劃專家,圍繞項目定位、主題特色、市場分析、業態布局、基礎設施配套、生態保護及運營模式等關鍵問題,進行了深入的咨詢與討論,提出了諸多建設性意見。
代軍對龍華鎮前期在旅游資源梳理和項目策劃方面所做的努力給予肯定。他指出,龍華鎮山水秀麗、文化厚重,發展旅游產業潛力巨大、前景廣闊。做好旅游開發項目策劃,是推動綠水青山轉化為金山銀山的關鍵一步。
就下一步工作,代軍提出明確要求:
一、堅持規劃先行,突出特色定位。 要牢固樹立“一盤棋”思想,將龍華鎮的旅游開發置于全縣乃至更大區域的發展格局中統籌謀劃。策劃方案必須深挖本地獨特的自然景觀、歷史文化、民俗風情等核心資源,找準差異化發展路徑,避免同質化競爭,精心打造具有鮮明標識度和強大吸引力的旅游品牌。
二、強化市場導向,優化業態布局。 項目策劃要深入研究客源市場需求與消費趨勢,科學規劃觀光游覽、文化體驗、休閑度假、康養研學等多元業態。要注重旅游要素的整合與提升,完善“吃、住、行、游、購、娛”產業鏈,推動旅游與農業、文化、體育等產業深度融合,培育消費新熱點,提升綜合效益。
三、嚴守生態紅線,實現綠色發展。 必須將生態保護放在首要位置,所有開發建設活動都必須遵循綠色、低碳、可持續原則。要嚴格評估項目對生態環境的影響,制定并落實最嚴格的保護措施,確保旅游資源永續利用,實現生態效益、經濟效益和社會效益的有機統一。
四、夯實基礎配套,提升服務品質。 要同步規劃、加快推進與旅游項目配套的道路交通、供水供電、污水處理、旅游廁所、停車場、智慧旅游系統等基礎設施建設。要加強對從業人員培訓和市場監管,著力提升旅游服務的標準化、精細化、人性化水平,讓游客來得方便、游得舒心、留下美好回憶。
五、創新機制模式,凝聚開發合力。 要積極探索政府引導、市場運作、社會參與的多元化投融資機制和運營管理模式。要加強與專業策劃機構、投資企業、運營團隊的對接合作,廣泛吸納各方智慧與資本。要充分調動當地群眾的積極性,保障他們在旅游發展中的知情權、參與權和受益權,實現共建共享。
代軍最后強調,縣級相關部門要主動作為,加強對龍華鎮旅游項目策劃和后續建設工作的指導與支持,幫助解決實際困難。龍華鎮要扛起主體責任,以此次調研和咨詢為契機,進一步修改完善策劃方案,細化工作舉措,明確時間表、路線圖,全力推動優質旅游項目早日落地見效,將龍華鎮打造成為我縣文旅融合發展的示范樣板和靚麗名片。
縣委常委、宣傳部部長,副縣長,以及縣發改、自然資源、文旅、交通、農業農村、生態環境等部門主要負責同志陪同調研并參加座談。