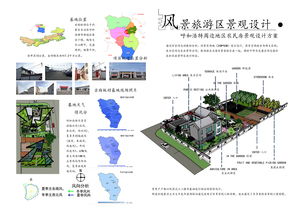
商丘作為河南省重要的歷史文化名城,擁有豐富的鄉(xiāng)村資源和獨(dú)特的文化底蘊(yùn),為鄉(xiāng)村旅游發(fā)展提供了廣闊空間。專業(yè)的鄉(xiāng)村旅游規(guī)劃設(shè)計(jì)公司、田園綜合體規(guī)劃設(shè)計(jì)以及旅游開發(fā)項(xiàng)目策劃咨詢服務(wù),正成為推動(dòng)商丘鄉(xiāng)村振興和旅游產(chǎn)業(yè)升級的關(guān)鍵力量。
鄉(xiāng)村旅游規(guī)劃設(shè)計(jì)公司可以通過深入調(diào)研商丘的鄉(xiāng)村特色,整合自然資源與人文遺產(chǎn),打造獨(dú)具魅力的旅游產(chǎn)品。例如,結(jié)合商丘的農(nóng)耕文化、民俗傳統(tǒng)和生態(tài)景觀,設(shè)計(jì)集觀光、體驗(yàn)、休閑于一體的鄉(xiāng)村旅游線路,提升游客的參與感和滿意度。
田園綜合體規(guī)劃設(shè)計(jì)則側(cè)重于將農(nóng)業(yè)、旅游、文化等元素深度融合,形成可持續(xù)發(fā)展的鄉(xiāng)村經(jīng)濟(jì)模式。在商丘,可以規(guī)劃以特色農(nóng)產(chǎn)品種植、農(nóng)事體驗(yàn)、鄉(xiāng)村民宿為核心的田園綜合體,帶動(dòng)當(dāng)?shù)鼐蜆I(yè)和收入增長,同時(shí)保護(hù)鄉(xiāng)村生態(tài)環(huán)境。
旅游開發(fā)項(xiàng)目策劃咨詢則為政府和企業(yè)提供專業(yè)指導(dǎo),從市場分析、項(xiàng)目定位到運(yùn)營管理,確保旅游項(xiàng)目的可行性和長期效益。商丘的旅游開發(fā)可以聚焦于歷史文化主題,如結(jié)合商丘古城、漢梁文化等資源,打造差異化旅游產(chǎn)品,吸引更多游客。
商丘在鄉(xiāng)村旅游領(lǐng)域的潛力巨大,通過專業(yè)的規(guī)劃設(shè)計(jì)和服務(wù),不僅能促進(jìn)地方經(jīng)濟(jì)發(fā)展,還能傳承和弘揚(yáng)鄉(xiāng)村文化,為游客提供獨(dú)特的旅行體驗(yàn)。